
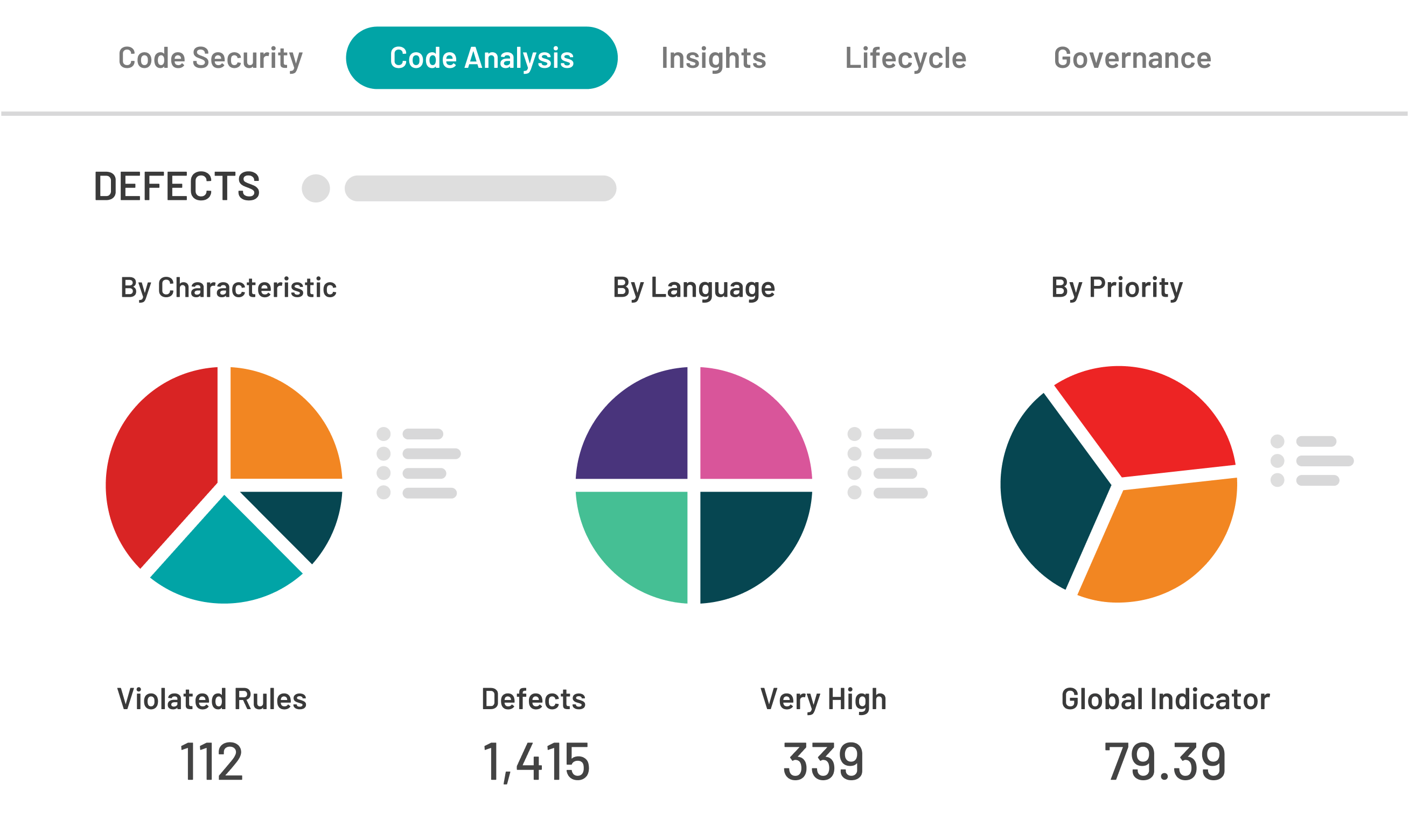


Risk-Based Prioritization for AppSec Teams
Risk-based prioritization is the practice of focusing vulnerability remediation on findings that pose genuine, exploitable risk rather than simply working through scan results in CVSS order. For AppSec teams, it’s…

