Introduction
Tainted Flow Analysis
Root cause of many security breaches is trusting unvalidated input:
- Input from the user is considered as tainted (possibly controlled by adversary), i.e user is considered as a untrusted source
- Data is used, assuming it is untainted (must not be controlled by adversary), i.e. sensitive data sinks rely on trusted (untainted) data
Source locations are those code places from where data comes in, that can be potentially controlled by the user (or the environment) and must consequently be presumably considered as tainted (it may be used to build injection attacks).
Sink locations are those code places where consumed data must not be tainted.
Tainted Flow Analysis
The goal of Tainted Flow Analysis is to detect tainted data flows:
For all possible sinks, prove that tainted data will never be used where untainted data is expected.
While Data Flow Analysis (DFA) is the computer technique to extract info about values at each program site, Tainting Flow Analysis (TFA) is a special case of DFA between sources/sinks for checking if non-neutralized external inputs may reach vulnerability sinks.
Kiuwan implements Tainted Flow Analysis by inferring flows in the source code of your application:
- What sinks are reached by what sources
- If any flows are illegal, i.e., whether a tainted source may flow to an untainted sink without going across a “sanitizer”
Tainting Propagation Algorithm: for each sink detected (typically, an argument expression to a call to a sick function), follow backwards the variable value propagation in the CGF (Control Flow Graph) that could affect the sink site, until a source site that “taints” any of the candidate variables is reached.
When inferring flows from an untainted sink to a tainted source, Kiuwan is able to detect if any well-known sanitizer is used, dropping those flows and thus avoiding to raise false vulnerabilities.
Data Neutralization Model
Complex subsystems that accept string data that may hold commands or instructions need neutralization of inputs targeted to them.
If untrusted input entering the subsystem may result in unexpected execution of commands/actions, an injection security flaw exists. Examples of such subsystems that are candidates for injection attacks are:
- Operating system command interpreter
- Data repository with SQL engine
- XML parser
- XPath / XQuery evaluator
- LDAP directory service API
- Script engines
- Regexp compilers (e.g. the pcre_replace() PHP function with /e pattern modifier)
Root cause of most web security flaws:
- Too much trust in external input (but HTTP request msg could be change ad-libitum by the hacker): headers (incl. cookies), request URL, body (incl. hidden fields).
- No adequate input validation / output sanitization / canonicalization – normalization.
The first defense line against application attacks is an adequate input validation.
- Should be positive, “accept only which is known to be good” (whitelist), not negative, “reject what is known to be bad” (blacklist).
- Sometimes output escaping is a good thing (e.g. against XSS; but less against SQLi and other attacks)
Good practice says: “filter on input, escape on output”.
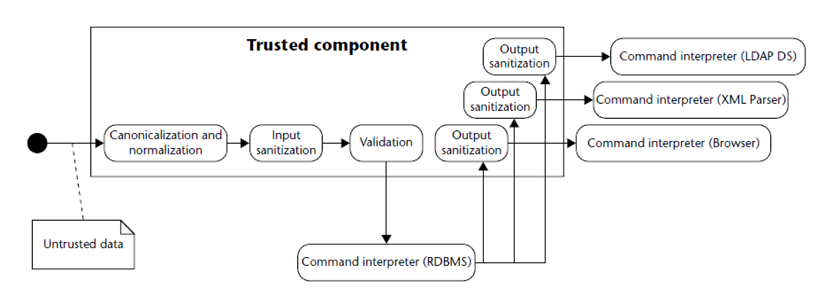
- Canonicalization / Normalization
- Canonicalization is the process of lossless reduction of input to its equivalent simplest known form (for example, replacing .. and . in a pathname to produce canonicalized pathname, Unicode canonical equivalence…).
- Normalization is the process of lossy conversión of input data to the simplest form (e.g. converting a text input into one value from a fixed set, removing accents, removing whitespace, stop words and punctuation chars, lower-/upper-casing…).
- Sanitization
- Ensuring that data conforms to the requirements of the subsystem to which it is passed, including security requirements related to data leakage or sensitive data exposure across trust boundary. This may include removal of unwanted characters, escaping metacharactes, etc.
- Validation
- Ensuring that input falls within expected domain of valid program input: type/numeric range requirements, input invariants…
Kiuwan contains a built-in library of sanitizers for every supported programming language and framework. These sanitizers are commonly used directly by programmers or by frameworks. And Kiuwan detects their usage.
But if you are using your own sanitizers, Kiuwan could not recognize them as such, detecting false “tainted data flows”. In this case, you should let Kiuwan be aware of them.
Goal of this section is to teach you how to incorporate custom sanitizers to the Kiuwan built-in library.
During the next section, we will use the terms “sanitizers” and “neutralization routines” as synonyms.
Neutralization Routines (a.k.a Sanitizers)
A Neutralization Routine (or Sanitizer) is understood as any piece of code that can assure that any tainted data got as input produces untainted as output.
This documentation is not related to how to build custom neutralization routines, but how to add your own custom neutralization routines to Kiuwan.
Basically, the process consists of:
- First, let Kiuwan know your routine
- Depending on the programming language you are analyzing, the so-called “routine” can be a function, a method of a class, etc.
- Second, let Kiuwan know that it’s a neutralization
- Kiuwan provides some ways to define your routine (we will see it later) but, regardless of it, you need to indicate that routine as “neutralization” .
Next, for instruction purposes, we will follow these steps using Java as the programming language. Differences with other programming languages will be further detailed.
Specifying custom neutralization routines
Any custom neutralization routine must be defined in a custom neutralizations file (xml format).
Name of the file is irrelevant but location is quite important.
Locations and precedence
Neutralization routines can be configured at different scopes
- Single-analysis,
- Application-specific and
- System-wide.
Depending on the location of the xml file, precedence and scope will change.
Precedence and scope of configurations is as follows:
- Single-Analysis
- Neutralizations can apply only to a unique analysis.
- In this case, the xml file should be located at:
[analysis_base_dir]/libraries/[technology]
- Application-specific
- Neutralizations can apply to all analyses of a specific application.
- In this case, the xml file should be located at:
[agent_home_dir]/conf/apps/[app_name]/libraries/[technology]
- System-wide
- Neutralizations can apply to all analyses of all applications.
- In this case, the xml file should be located at:
[agent_home_dir]/conf/libraries/[technology]
- Exceptions to this rule are:
- cpp engine reads from …/libraries/c
- objective engine reads from …/libraries/objetivec and …/libraries/c
Legend
[agent_home_dir] : local installation directory of Kiuwan Local Analyzer (KLA)
- [analysis_base_dir] : root directory of application source code to be analyzed, as specified by “-s” option of KLA CLI (Command Line Interface), or in “Folder to analyze” input box when using KLA GUI (Graphical User Interface)
- [app_name] : name of the app to be analyzed, as specified by “-n” option of KLA CLI (Command Line Interface), or in “Application name” input box when using KLA GUI (Graphical User Interface)
- [technology] : name of the Kiuwan technology, as specified in [agent_home_dir]/conf/LanguageInfo.properties
Be careful
Never save custom libraries files or edit existing files in folder [agent_home_dir]/libraries/{tech}, because this folder is going to be removed when the engine is updated.
As a general recommendation, we suggest to name the xml file as [technology]_custom_neutralizations.xml (this will help to clearly identify your custom files from Kiuwan own files).
Therefore, next sections will use java_custom_neutralizations.xml as the name for our custom file.
Creating a custom “Library” of neutralization routines
Obviously, you don’t need to create an xml file for every single neutralization routine.
Instead, you will include all of them in a single file identified as a “library” of custom neutralization routines, with a “name” for it.
Library identification will be a XML element such as:
<library name="java.custom.libraries"/>
As a suggestion, we recommend use something as “[technology].custom.library”
Please, refer to technology-specific DTD for available “library” attributes.
As said above, a Neutralization Routine is a piece of code that assures that any tainted data got as input produces untainted data as output.
That piece of code is typically a function or a class method (depending whether your technology is object-oriented or not).
Then, what you must do in the XML file is to properly declare such “routine” and mark it as a neutralization routine.
To declare the routine, you must include the element. Every technology-specific DTD describes the allowed set of elements that form part of the “library”.
For our purposes, commonly used elements are either “class” or “function”, depending on the language. Please, see those specific DTDs for the allowed set of elements.
Once, the routine is “declared”, must be “marked” as a neutralization routine as follows. See the reference section for more details on how to declare a routine.
Examples
Let’s see some explained examples of custom neutralizations:
Example 1 (Java)
In this example the method validate is a custom neutralization for a path from a source to a path traversal sink. The input of method validate is neutralized and the output, (referred by argpos -1 in the neutralization definition in the xml library), is untainted after the validation is executed.
The next source code shows an example of how to use the neutralization:
package com.mycompany.onepackage;
import com.mycompany.otherpackage.MyUtils;
import javax.servlet.http.HttpServletRequest ;
import java.io.FileInputStream;
public class MyClass {
// ...
public void methodThatAccessToFileSystem(HttpServletRequest req) {
String inputFile = req.getParameter("file"); //inputFile tainted
inputFile = MyUtils.validate(inputFile + ".tmp"); //inputFile untainted after validation
return new FileInputStream(SAFE_DIR.getAbsoluteFile() + inputFile);
}
// ...
}
=======================================
package com.mycompany.otherpackage;
import com.mycompany.IMyUtilsClass;
public class MyUtils implements IMyUtilsClass {
// ....
public String validate(String value) {
// ...
// perform string value validation/Canonicalization/Normalization/Sanitization
// ...
return value; // once cleaned up
}
}
And this is how you should declare the neutralization method in the library xml file:
<!DOCTYPE library SYSTEM "library_metadata.dtd">
<library name="java.custom.libraries">
<class name="com.mycompany.otherpackage.MyUtils" kind="class" supertypes="com.mycompany.IMyUtilsClass">
<method name="validate" signature="validate(java.lang.String)" match="name">
<return type="java.lang.String"/>
<neutralization argpos="-1" kind="path_traversal" resource="web" />
</method>
</class>
</library>
Do not forget
- types has to be fully qualified
- specify return type if the method has one
- no need to declare parameters names in the method signature, just the fully qualified types
Neutralization argpos, kind and resource arguments will be discussed later...
Example 2 (Java)
In the next example the neutralization only affects to filesystem resources:
package com.mycompany.onepackage;
import com.mycompany.otherpackage.CustomFile;
import javax.servlet.http.HttpServletRequest;
import java.io.FileInputStream;
public class MyClass {
// ...
public void methodThatAccessToFileSystem(HttpServletRequest req) {
String inputFile = req.getParameter("file"); //inputFile tainted
CustomFile file = new CustomFile(inputFile);
file.sanitize(); //file untainted after sanitization
return new FileInputStream(SAFE_DIR.getAbsoluteFile() + file);
}
}
=====================================
package com.mycompany.otherpackage;
import java.io.File;
public class CustomFile extends File {
//..
public void sanitize() {
// perform file sanitization
}
}
Neutralization declaration in the library xml file:
<!DOCTYPE library SYSTEM "library_metadata.dtd">
<library name="java.custom.libraries">
<class name="com.mycompany.otherpackage.CustomFile" kind="class" supertypes="java.io.File">
<method name="sanitize" signature="sanitize()">
<neutralization argpos="-2" kind="string" resource="filesystem"/>
</method>
</class>
</library>
Neutralization elements
A neutralization is defined in Kiuwan by the following element:
<!ELEMENT neutralization (#PCDATA)*> <!ATTLIST neutralization argpos CDATA #REQUIRED kind CDATA #IMPLIED resource %resource; #IMPLIED >
argpos
argpos
argpos attribute specifies the “tainted” object, i.e. what object (or objects) are “untainted” by the routine.
In a typical method call, there are several objects involved:
value = obj.call( arg1, arg2)
The neutralization routine can “untaint” one or many of those objects.
argpos attribute specifies which ones, as follows:
- “-2” : untainted object will the caller to the routine => obj
- “-1” : untainted object will the returned object => value
- “0 … n” : argument with that index will be untainted => arg1 if 0, arg2 if 1, both if 0,1
kind
A neutralization routine is usually applied to a specific vulnerability type (or “kind”).
kind
kind attribute indicates the kind of vulnerability affected by this neutralization, like "xss", "sql_injection", "open_redirect", etc.
To see the exact attribute value, locate the vulnerability you need to neutralize, open the sink data and see Category value.
You can include as many neutralization elements as vulnerability types your routine neutralizes.
<neutralization argpos="-1" kind="sql_injection"/>
<neutralization argpos="-1" kind="xss"/>
In case you want the neutralization applies to ALL the vulnerabilities (i.e. it’s not specific to any vulnerability), set “string” as the value for “kind” attribute
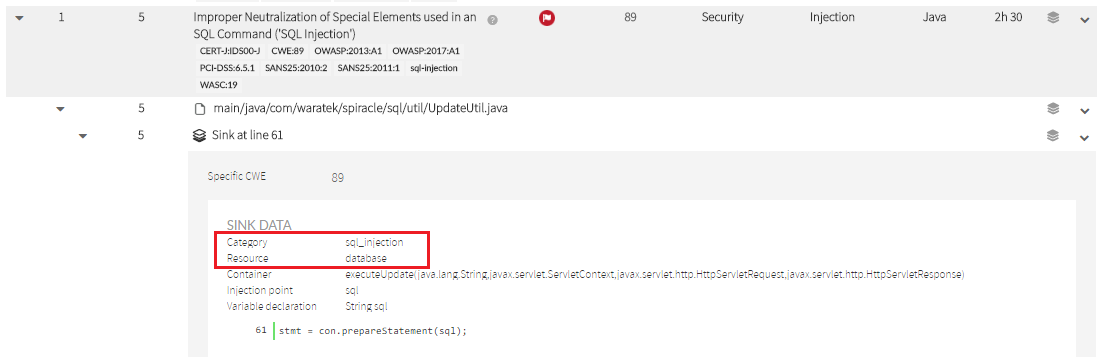
resource
A neutralization routine also can be specifically suited to a particular resource type.
For example, your neutralization routine could be applied to “database” or “filesystem” resource types.
Valid values of resource can be one of (memory |os |configuration |environment |filesystem |formatstr |database |web |network |gui |crypto |other).
As above, check the Sink Data to set the appropriate value. That’s the value you must indicate in “kind” attribute.
Reference
Structure of Custom Neutralization File (CNF)
Any CNF must be an XML file with the following structure:
- Reference to “master” DTD
- Definition of the custom Library of Neutralization routines
- List of custom Neutralization routines
Next sections describe this structure.
Reference to master DTD file
Reference to master DTD must be specified in the 1st line.
Next table shows specific content depending on the technology:
Tech | DTD specification | DTD location |
|---|---|---|
abap | <!DOCTYPE library SYSTEM "abap_library.dtd"> | [agent_home_dir]/libraries/abap |
c / cpp | <!DOCTYPE library SYSTEM "cpp_library.dtd"> | [agent_home_dir]/libraries/c |
csharp | <!DOCTYPE library SYSTEM "library_metadata.dtd"> |
|
java | <!DOCTYPE library SYSTEM "library_metadata.dtd"> |
|
javascript | <!DOCTYPE library SYSTEM "js_library_metadata.dtd"> | [agent_home_dir]/libraries/javascript |
objectivec | <!DOCTYPE library SYSTEM "library_metadata.dtd"> |
|
php | <!DOCTYPE library SYSTEM "php_library.dtd"> | [agent_home_dir]/libraries/php |
python | <!DOCTYPE library SYSTEM "python_library_metadata.dtd"> | [agent_home_dir]/libraries/python |