Are all active rules needed ?
In a large analysis (for example, with thousand of files), you most probably will only be interested in “important” defects. importance verylowLow priority rules will generate thousands of non-important defects that will increase the resources needed for your analyses.
| Info |
|---|
Try to focus on your analysis needs. Avoid generate more defects than needed. Use a model that best suit your needs, activating only those rules that are really important for you. To activate only important rules is the most efficient way to execute the analyses as well as to “consume” the produced results. |
Reasons for mute defects can be of different nature, being the most common to hide defects that are considered false positives.
But muting a defect is supposed to be something ocasional.
Bear in mind that muting a rule only “hides” its defects, but the rule is still being executed.
- If you are muting too many false positives, you should immediately contact Kiuwan Technical Support (and deactivate that rule).
- If the reason to mute a rule is because the discovered defects do not apply to your application or because are not of your interest, deactivate the rule.
You will speed up the analysis process and make your analyses more manageable.
Please visit https://www.kiuwan.com/docs/display/K5/Models+Manager+User+Guide on how to deactivate rules and managing Kiuwan models
analyzing Java for The advantage to a higher vulnerabilities spread and the false SQL analyses .And this association is used by KLA to execute the adequate engine on the source files.
See https://www.kiuwan.com/docs/display/K5/Kiuwan+Supported+Technologies for a full detail on extensions technologies.But sql is a typical example, it matches PLh are also the case for C
Instead, when running in CLI mode, by default KLA will execute (in the sql case) the three available sql engines, wasting time and resources and producing confusing results (as will generate defect information from all those engines and corresponding rules).
An easy way to avoid unnecessary processing is specifying supported.technologies parameter with only the proper technologiesIf you know that you are analyzing PL_SQL, be sure to delete Transact and Informix from the list of supported technologies.
For further info please visit Command Line Interface - SupportedTechnologies
Another example, it’s quite common to analyze applications that include export/import SQL scripts.
These scripts are usually huge files. If you do not exclude those script files, and do not change default sql configuration, Kiuwan will analyze those huge files with all the sql engines.
You can imagine the waste of time and resources ...| Info |
|---|
As general rules:
|
.aka clone a memory and cpu intensive Nevertheless allows to then
As you can read in the above article, ignoring literals and identifiers its a “smart” way to find clones, but in many circumstances it’s not obvious to understand.
Most of the times, we want to identify duplicated code as “identical” code.
You can set this way of working (i.e. only detecting identical code blocks) by specifying the following properties:
There’s a couple of aspects that affects resource consumption (mainly memory and execution time):
how to manage literals and identifiers
the minimum number of tokens a clone must have
This article (https://www.kiuwan.com/blog/avoid-duplicated-code-with-clone-detector/) explains how clone detector works and the different ways of configuring it.
If you are not interested at all in duplication code analysis, you can make Kiuwan not execute it:
|
Kiuwan’s clone detector searches for fragments of tokens that are very similar.
The term ‘token’ refers to each of the atomic elements identified by the analyzer. There are three types of tokens:
- Operators and reserved words (specific for each language)
- Identifiers: variable names, function names, etc.
- Literals: numbers and string constants used in the code.
Kiuwan also generates defects of ‘duplicated code’ according to the size of the fragments found:

You can configure the minimum tokens that Kiuwan uses to detect a clone. This is done at two levels:
a) In Kiuwan’s Local Analyzer go to Advanced options, then configure the number of tokens to detect a clone. You can configure a different number of clones for each language.
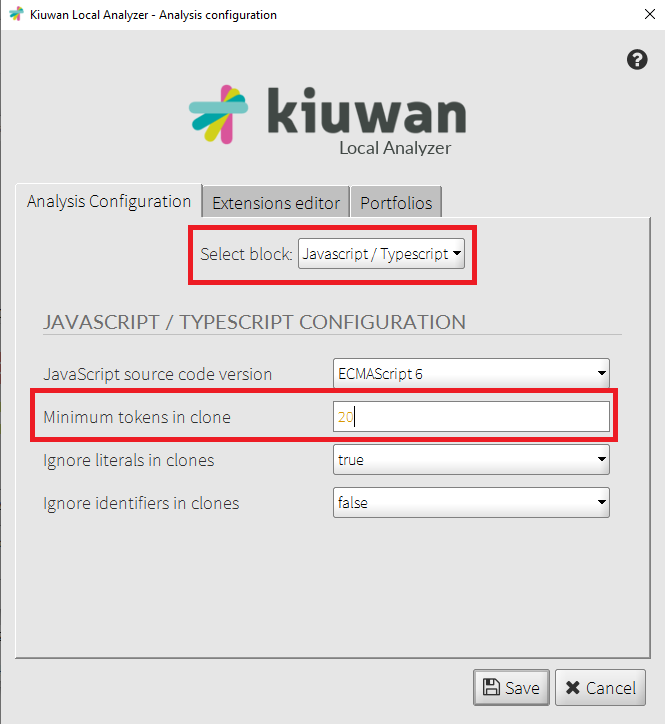
b) In your model, configure the minimum tokens to generate a ‘Duplicated code’ defect.
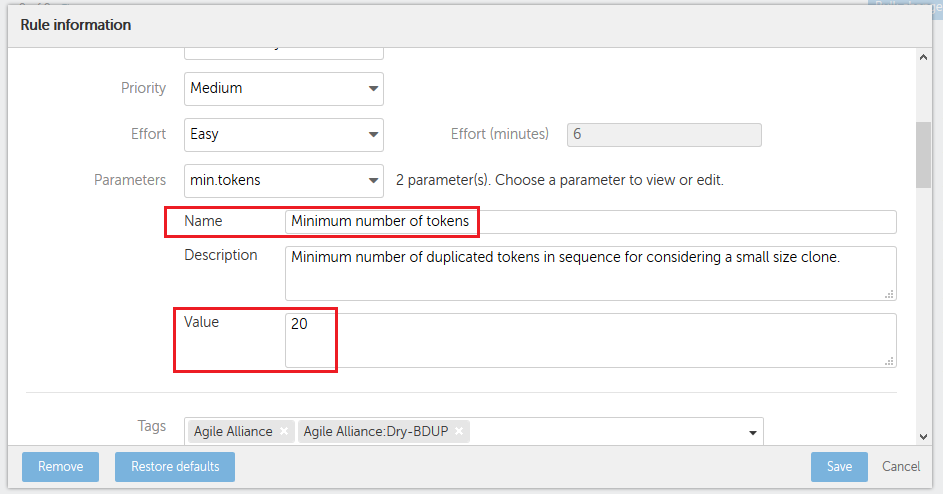
Depending on this configuration, Kiuwan gets different results in the clone detection. Let see these in detail.
The most conservative way
In this case, we configure Kiuwan to look for an exact match between the differents fragments:
{language}.min.tokens=20
{language}.ignore.literals=false
{language}.ignore.identifiers=false
Taking this source code as example:
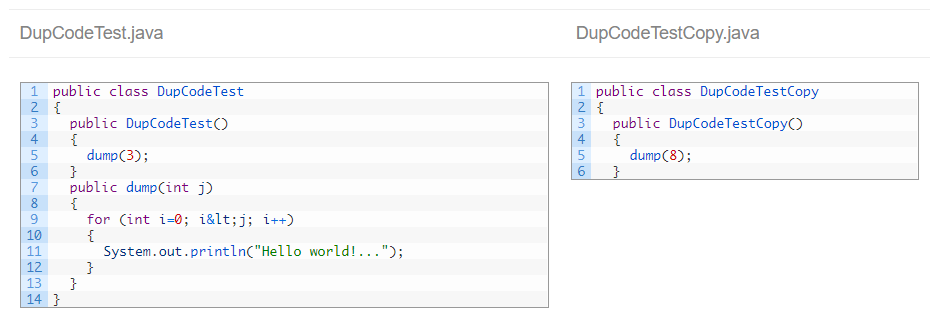
Kiuwan detects duplicate code:

IMPORTANT: The ‘clone’ begins at the close parenthesis of line 5, but Kiuwan prints the complete line. This may be a little messy sometimes.
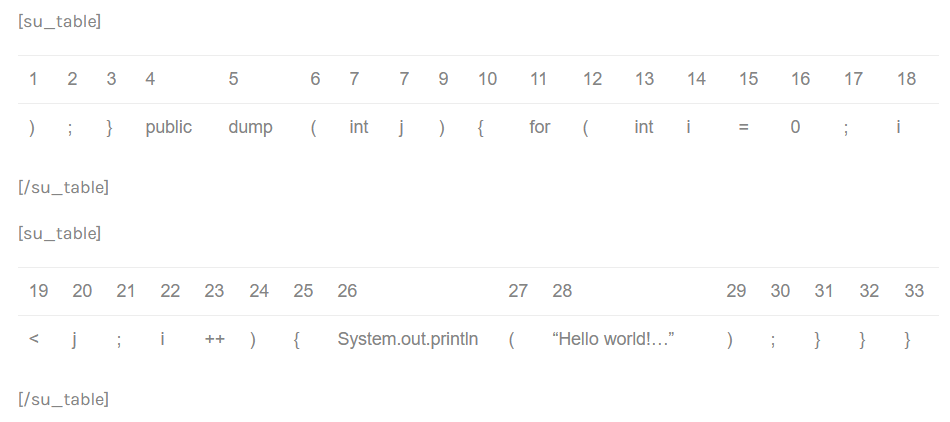
The detected tokens are:
Set the clone detector to be smarter
Now we are going to configure Kiuwan to ignore the numbers and string constants in our code:
{language}.min.tokens=20

As you can see in the picture above, now the fragment is bigger because the literals (‘3’ and ‘8’) are not taken into account.
The third option
As the third option, we can ignore literals and identifiers:
{language}.min.tokens=20
{language}.ignore.literals=true
{language}.ignore.identifiers=true

With this last option, the most efficient one, it was clear that class DupCodeTestCopy is really a copy-paste where the class was only renamed, so Kiuwan detects the whole class as a clone.
But this configuration is also the one most prone to false positives. For example:
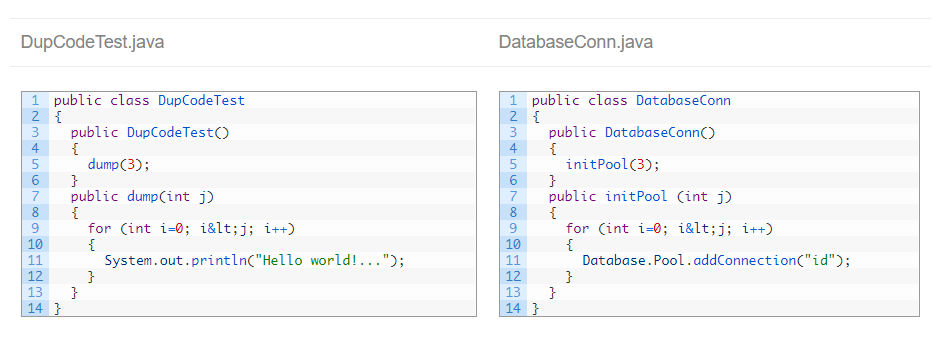
Both files have a similar structure, but functionally they are very different. Ignoring literals and identifiers, Kiuwan considers both a clone:

If clone detector raises many duplicated blocks, increase the number of tokens.
Doing so, there will be less clones, reducing this way the amount of memory needed to execute the clone detection process.
| Info |
|---|
Just in case you are not interested at all in duplication code analysis, you can make Kiuwan not to execute it.
|